啥也没整理,鹦鹉学舌,都是书上现有的东西。
第一章
第一章啥也没有,跳了。
也许有点啥,但我白兰。
第二章
- 将
的非负整数 次幂,即 快速转置成十六进制: 将
表示成 的形式,转置后的十六进制即为 面跟着 个十六进制的 。
如
- 十六进制跟十进制的转换和数字逻辑里一致,不赘述。写在这里是让你回想一下。
防止记不起来还是给一张图
- 字节这块需要注意的是,32位和64位常用的数据类型中,不同的是long,在32位上是4字节,64位上是8字节。char *也有区别,但考虑的相对较少。
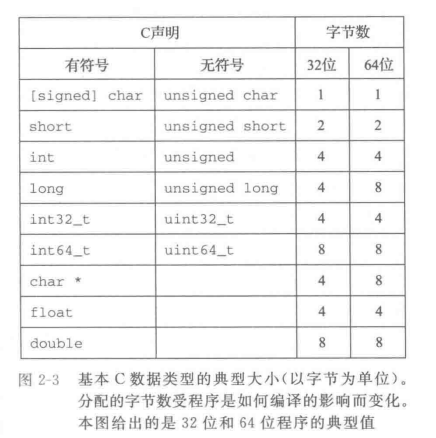
ISO C99中引入了数据大小固定的数据类型。其中就有int32_t和int64_t,分别为4个字节和8八个字节。
大部分的编译器和机器都认为
是有符号数据类型,但实际上C标准不保证这点。所以其实需要程序员声明 是有符号的。 但实际上这点根本无所谓。
大端法和小端法
给一个三级标题是因为这个东西是考试重点,后面也一样。
大端法
即最高有效字节排列在前面的方式。
是符合人类直觉的正常数字排列。
Sun是大端法机器。
小端法
将最低有效字节排列在前面的方式。
linux 32和Windows和Linux 64均为小端法机器。
需要注意的一点是,实际上机器代码中按照大端和小端排列的只有立即数的部分,而表明操作的代码不按照这个来。
(图中右侧代码从下往上读)
对齐
(PPT上有但我怀疑不用考)
按边界对齐(假定存储字的宽度为32位,按字节编址)(图上)
- 字地址:4的倍数(低两位为0)
- 半字地址:2的倍数(低位为0)
- 字节地址:任意
不按边界对齐 (图下)
坏处:会增加访存次数
关于对齐的样例
1
2
3
4
5
6
7
8
9
10
11struct S1{
int i;
char c;
int j;
}
struct S2{
int i;
int j;
char c;
}在要求对齐的情况下,结构体S2优于结构体S1。
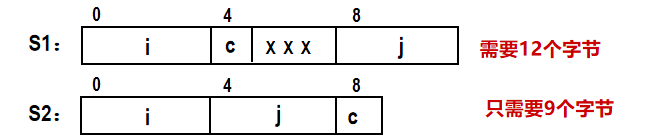
同时考虑对于struct S2 d[4]需要分配几个字节。(数组)
布尔运算
这个布尔运算就是与或非异或同或那一套,数电里有详细说明,这里就不赘述了。
提一下。
确定一个位级表达式的结果最好的方法,就是将十六进制的参数扩展成二进制表示并执行二进制运算,然后转换回十六进制
注意:要区别
和 ,&和&&,~和!。(这三组中,前者都是算数运算符,后者都是逻辑运算符)
注意:|和&的逻辑运算符第二个重要的区别就是如果逻辑运算符中,如果对第一个参数求值可以得到表达式的结果,则不会对第二个参数求值。比如说a&&5/a不会导致被零除,p&&p++也不会访问空指针。
- 掩码运算
掩码表示的是一个位模式,即从一个字中选出的位的集合。(就是从一个长串里挑几位出来)。举一个例子,掩码0xFF(最低八位为1,其余为0)表示一个字的低8位字节。令a为一个字,则a&0xFF就表示为a的最低八位。
这类操作非常普遍,而且有许多精彩的操作,后续讲例题的时候会提到。
移位运算
首先提一点,一个长为
左移
左移操作均为逻辑左移。x << k即表示为。同时,移位操作时满足结合律的,x << k << j == x << j << k
移位后得到[] 右移
- 逻辑右移
逻辑右移在左端补个0,x >> k表示 。
即移位后得到[] - 算数右移
算数右移在左端补个最高有效位的值。
即移位后得到[]
- 逻辑右移
所有机器对无符号数默认使用逻辑右移,有符号数默认算术右移。
Java中,x >> k表示算术右移k个位置。x >>> k表示逻辑右移k个位置。C中没有这个写法。
移动k位,这里的k很大
假设对于一个位的数据类型,如果想移动 位,那么会有什么结果呢? 在某些C标准中,会移动
mod 位,比如说在 =32时,移动36位就是移动4位。但这在C程序中并不是一定成立的,所以最好还是让移动位数小于 。
但这在Java中是一定成立,这在Java中被特别要求。关于移位的运算优先级
移位的运算优先级低于加减法。这一点有点反直觉,因此不确定的时候最好都加上括号。
有符号数的除以2的幂
向右算数右移。
有符号数直接右移
加上偏置值之后右移
所以表达式
IEEE浮点表示
为啥其他的不说先说这个捏。
因为这个我是真不会。
- IEEE浮点标准
的形式表示一个浮点数 是符号位 是尾数。其范围是 到 ,不一定对应 的作用是对浮点数加权,这个权重是2的 次幂(可能是负数),也不一定对应
然后有两种常见的格式,每种格式中都定死了
分别为float和double。
如图:
float:
double:
根据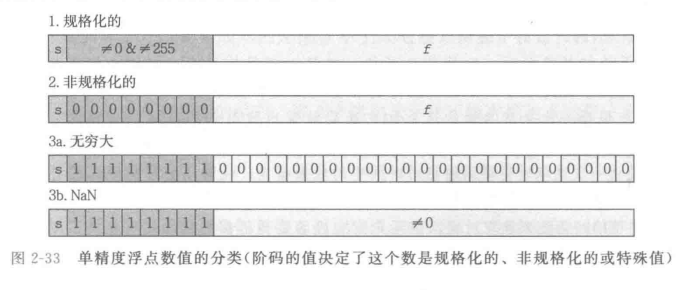
规格化的值
此时的位模式不全为1也不全为0。
这时要加上偏置值的形式: 指的是此时 总的符号位,所以单精度时 ,双精度时 这个偏置值和有符号算数位移的偏置值算法不一样,那个是
同时小数点在最高位的左边,也就是说整个 都在小数点右边。 非规格的值
的位全为0的时候,表示的就是非规格的值。
这种情况下:特殊情况:
的位全为1 - 如果
全为0,那么表示无穷大, 为1是负无穷, 为0是负无穷 - 如果
不是0,那么表示的就不是一个数字。
- 如果
以上就是知道的所有知识了。
下面的图是个example,用来确定思路用的。爱看不看。
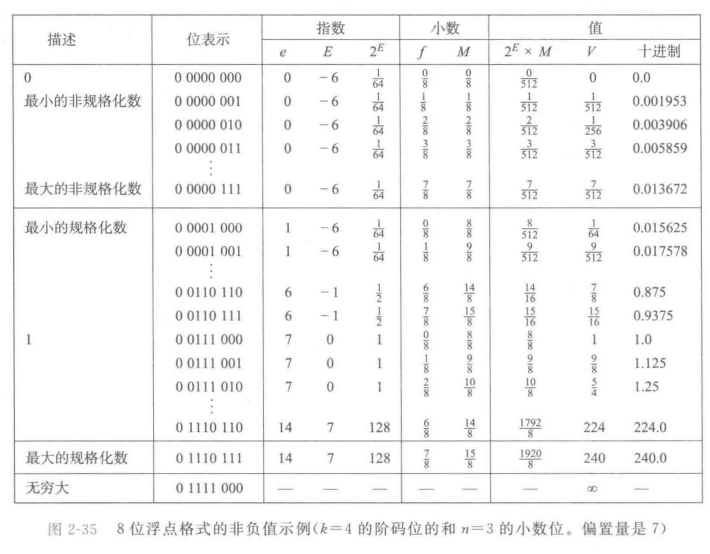
舍入
根本没看,完全不懂,以后补上。
浮点运算
实话实说,这一块我是根本没看懂,属于是先记下来,以后再看。
浮点数的加法
- 不具备结合性。
(会导致舍入)
比如说(其中 是double, 是float) - 满足单调性,且这一点是无符号加法和补码加法都不满足的。
即如果有浮点数,那么对于任意值的 ,都有
- 不具备结合性。
浮点数的乘法
- 满足可交换性
- 不具备结合性
- 不具备分配性
强制转换
- 执行一个运算,只要其中有一个数是无符号数,就会把其他数值全部转换为无符号数并进行运算。
sizeof函数返回的值是一个无符号数。
- 将short转换为unsigned时,我们要先改变其大小,之后再完成从有符号到无符号的转换。
- 从int到float,数值不会溢出,但是可能被舍入
- 从int或者float到double,可以保留精确的数值
- 从float或者double到int,值会向0舍入。同时,也可能会溢出。
第三章 程序的机器级表示
***的汇编。
汇编代码中所有以’.’开头的都是指导汇编器和链接器工作的伪指令,也就是说都是可以忽略的废话。
就像这种东西:
关于如何用
生成Inter格式的汇编代码
>linux> gcc -Og -S -masm=interl xxxx.c(文件名)
至于Intel格式和ATT的区别:

- 可以在C程序中加入汇编代码来提高效率。但书上提的两种方法我都没看懂。所以不细说了。
gcc和objdump命令
连续考了两年,记一下。
gcc指令:
-
>linux> gcc -g aa.c -o aa
对aa.c生成可执行文件,存储在aa。 >linux> gcc -c aa.c
对aa.c生成可执行文件,并命名该文件为aa.o(可执行文件后缀为o,内容为二进制机器码)>linux> gcc -s aa.c
对aa.c生成汇编文件,命名该文件为aa.s
-
objdump生成反汇编指令文件
>linux> objdump -d foo > foo.s
对foo(可执行文件)反编译,得到的文件存储在foo.s(汇编文件)>linux> objdump -d foo
对foo反编译,生成名为foo.s的汇编文件。
数据格式
这玩意儿经常用,mark一下。
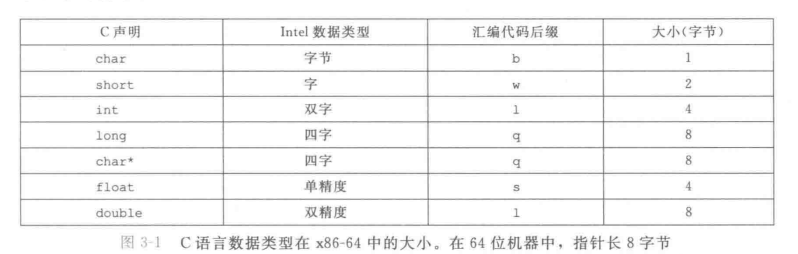
记住bwlq,然后指针和long一致就完事了。
单精度和双精度用的是一组完全不同的指令和寄存器。所以double和int后缀相同并不会导致问题。
- 单精度浮点4个字节,双精度8个字节,X86历史上还有一个long double的浮点形式,十个字节。但是不咋好用,精度低不好移植,用的也少。
通用目的寄存器
背!

上面的63,31,之类的标识指的是对应的位长,比如说eax寄存器有32个位,rax就是64个位。借此来访问寄存器的不同位置。
低于64位的寄存器不能用来储存地址,比如说%ebx就不能用来储存地址。
- 把数据从其他位置迁移到寄存器里时,有两条规则。
- 1.生成1字节或者2字节数字的指令会保持寄存器剩下字节不变。
- 2.生成4字节数字的指令会把高位4个字节置0.
- 3.生成8个字节当然就占满了。 (2条规则当然有三点)
注意栈指针%rsp,用来指明运行时栈的结束位置。有些程序会读写这个寄存器。
操作数地址
背!

带r的就是寄存器,Imm指的是立即数,M指的是内存。
$Imm的操作数就是Imm。很直观。
注意:格式里不存在括号里同时有三个寄存器的模式。这个考了两年。
数据传送指令
背!
其实也不用背。看看就懂了。和上面说的差不多。
movabsq下面会讲。
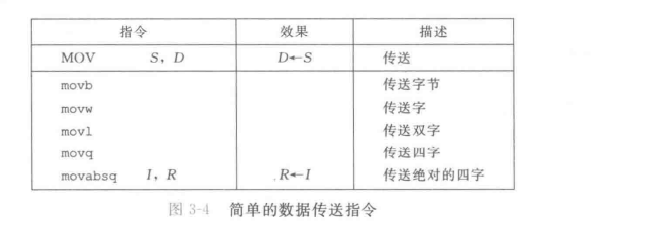
- 源操作数可以是一个立即数,可以在寄存器后者内存,目的操作数可以指定到一个位置,一个寄存器或者一个内存地址。
注意: x86-64加了条限制,两个操作数不可以都指向内存地址。将一个值从内存移到内存,需要两条指令,一条把值移到寄存器,一条把值从寄存器复制到目的内存。
大部分时候,
指令只会更新目的操作数指定的寄存器字节或者内存位置。唯一的例外是 指令,会把目标寄存器的高位4字节变成0。(这个上面说过了,再说一遍)
原因是x86-64采用的牛逼惯例:任何寄存器生成32位值得指令都会把该寄存器得高位部分变成0。关于
和 :
常规的操作,其如果要以立即数为源操作数,那么这个立即数只能是32位的补码数字,然后把这个数符号扩展成64位。(也就是说不能直接操作64位立即数)。但 可以以任意64位立即数值作为源操作数,但是只可以以寄存器作为目的。 将较小源值复制到较大的目的的时候:
一般这个时候要考虑位的扩展,所以指令也有零位扩展和符号扩展两种。如下:是零位扩展, 是符号扩展。
反正就后缀的俩字母,前面的那个是源码格式,后面的那个是目的格式。好记。
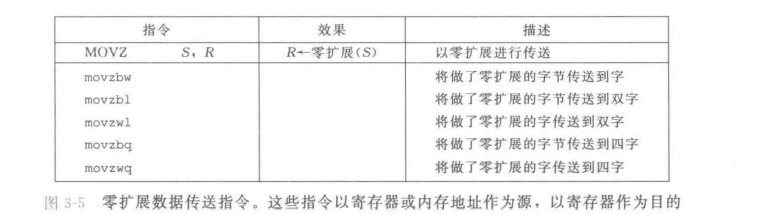
这里没有
,也就是没有四位到八位。但实际上这个零扩展操作直接用 就可以实现,这依靠于x86的牛逼惯例。
经过神的提点,教材里关于上面这句关于的语句并不严谨,实际上 和 并不等同,只是说类似于 %eax %ebx的操作可以得到 %eax %rbx的效果。, 的源操作数和目的操作数仍然受其本身的限制。
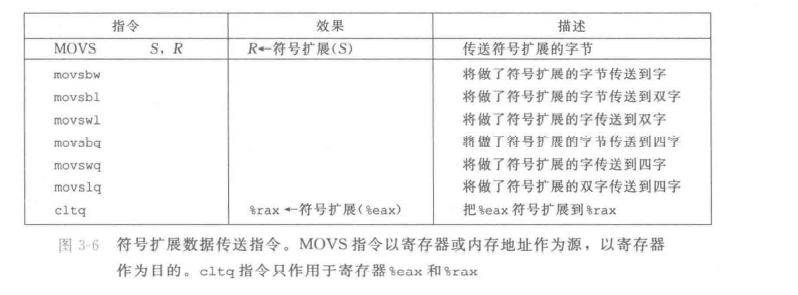
注意到这里头有个
,这个只能以%eax作为源,%rax作为符号扩展的目的,跟 %eax %rax实际上一个意思,但是写起来更短更紧凑。
- 注意:移位指令中,使用符号拓展还是零位拓展取决于源操作数的数据结构,而不是目的操作数的数据结构。
汇编指令纠错
- 寄存器和指令后缀不匹配/两个寄存器位数大小不一样
- 两个参数都是内存地址
- 用非64位的寄存器作为内存地址
- 寄存器不存在
- 立即数作为目的
- 操作数的写法格式有误。如(rax,rbx,rcx)。
压入和弹出栈数据
栈顶元素时所有栈中元素地址中最低的,地址向栈底依次增大。
push指令是压入,pop是弹出,%rsp保存栈顶元素的地址。
就很基础,所以放一起说了。将一个四字值压入栈中,首先需要将栈指针减8,然后将值写到新的栈顶地址。
所以pushq %rbp(把%rbq的值压入栈)等价于下面两条指令:
subq $8,%rsp
movq %rbp,(%rsp)
弹出栈同理
popq %rax等价于下面两条:
movq (%rsp),%rax
addq $8,%rsp
不过pop和push只需要一个字节,执行相同效果的两条指令要八个字节。
- x86-64中,栈是向低地址方向增长的,所以压栈要做的是减小%rsp的值,出栈要增加%rsp的值。
算数和逻辑操作
看图
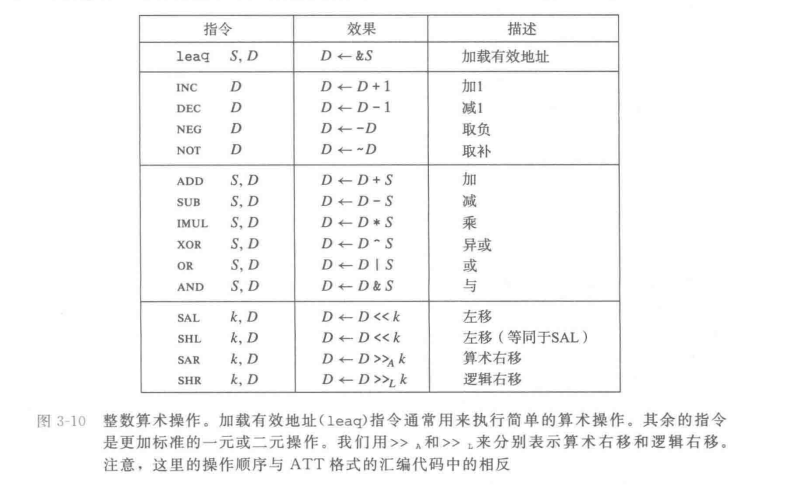
加载有效地址(lea)
leaq这个指令和mov不同的在于,这条指令不是从指定的位置读入数据,而是将有效地址写入目标操作数。
打个比方,如果%rdx里头的值设为x,而x+8的地址内存储y,那么
leaq 8(%rdx),%rax
就是将%rax的值设为x+8,而
mov 8(%rdx),%rax
指的是把%rdx+8指向的值存入x,也就是把%rax设为y。
注意:lea的目的操作数只能是寄存器
- 一元操作的操作数可以是寄存器/内存。二元操作的操作数可以时立即数/寄存器/内存,目的操作数可以是寄存器/内存。
移位操作
SAL和SHL差不多,都是左移然后在右边补零。但SHR和SAR不一样,SHR是逻辑右移,SAR是运算右移(按照最高位的值来补位)。
移位操作的移位量要么是一个立即数,要么是单字节寄存器%cl中的值(只能是这一个寄存器)。
但以%cl作为移位量时,实际的移位量会根据移位指令的数据格式从%cl中取数,由%cl中的低m位决定(二进制),这里,而更高位会被忽略,举一个例子: 当%cl中的十六进制值为0xff时,指令salb会移7位,sabw会移15位,sall会移动31位,salq会移动63位。(反正不能超过对应数据格式的最多位数)
同时salb只看%cl中二进制的最低3位,salw只看最低4位,依次递推。
特殊的算数操作
这块其实讲的就是怎么在64的情况下得到128位的乘积。
但好像不考。先跳了。

这几条指令中提供的
%rdx存储高64位,%rax存储低64位。
如果是除法,那么除完之后的商放在%rax,余数存储在%rdx。
指令clto可以把%rax的符号位复制到%rdx的所有位。这条指令不需要操作数。
条件码
- CF:进位标志。最近的操作使最高位产生了进位或者借位。用来检查无符号位的溢出。
- ZF:零标志。最近的操作得到的结果是0.
- SF:符号标志。最近的操作得到的结果是负数。
- OF:溢出标志。最近的操作导致一个补码——正溢出或者负溢出都行。
lea指令和mov指令都不改变条件码。
test指令的运算规则和ADD一样,唯一的区别是test不会更改目的操作数里的值。
- test的典型用法:
- 两个操作数是一样的,用来检查是正数,负数,还是0.
- 其中一个操作数是掩码,用来指示哪些位应该被测试。
访问条件码
set指令的目的操作数是低位单字节寄存器元素之一(如al),或是一个字节大小的内存地址。以此时的标志码为根据,将这个字节设为0或者1.
set指令的作用可以根据后缀与cmp指令连用来理解。
如:
1 | cmp %rbx %rcx |
就是在%rbx与%rcx储存值相等时,将%al的值设为1.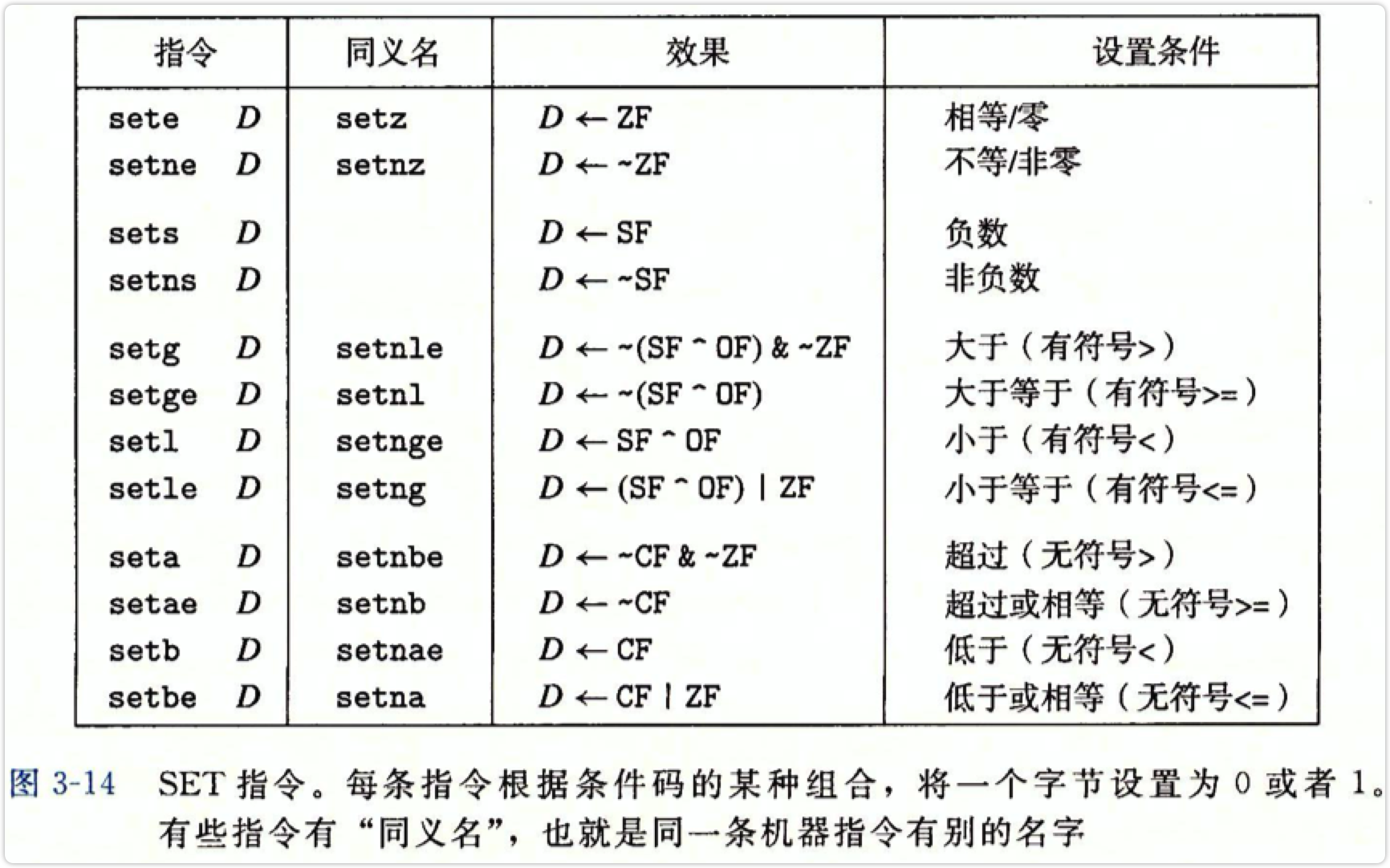
注意这里的后缀l和b指的不是操作数的大小。
注意有符号和无符号用的后缀是不同的:
- 无符号的大于后缀是a,小于后缀是b(below)
- 有符号的大于后缀是g(greater),小于后缀是l(less)
跳转指令
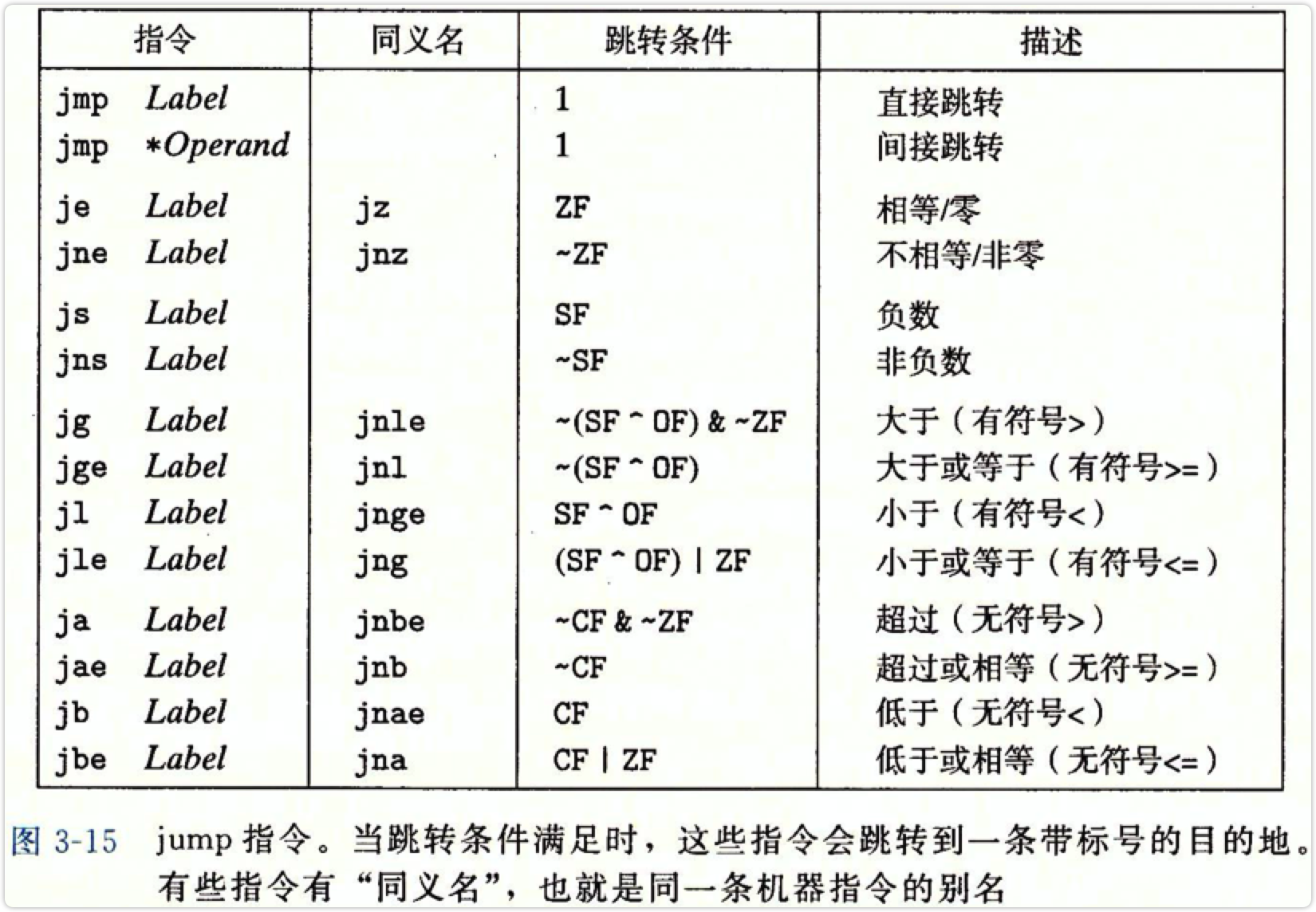
- jmp指令作为无条件跳转,可以是直接跳转或者是间接跳转。
- 直接跳转就是直接跟一个地址立即数。
- 间接跳转:
如 jmp *%rax
就是以%rax中的值作为跳转目标。
其余的所有条件跳转只能是直接跳转
条件跳转的后缀命名规则和set指令一致,不赘述了。
- 跳转指令的机器编码
先不写,这一块书上写的很迷惑。
条件传送指令
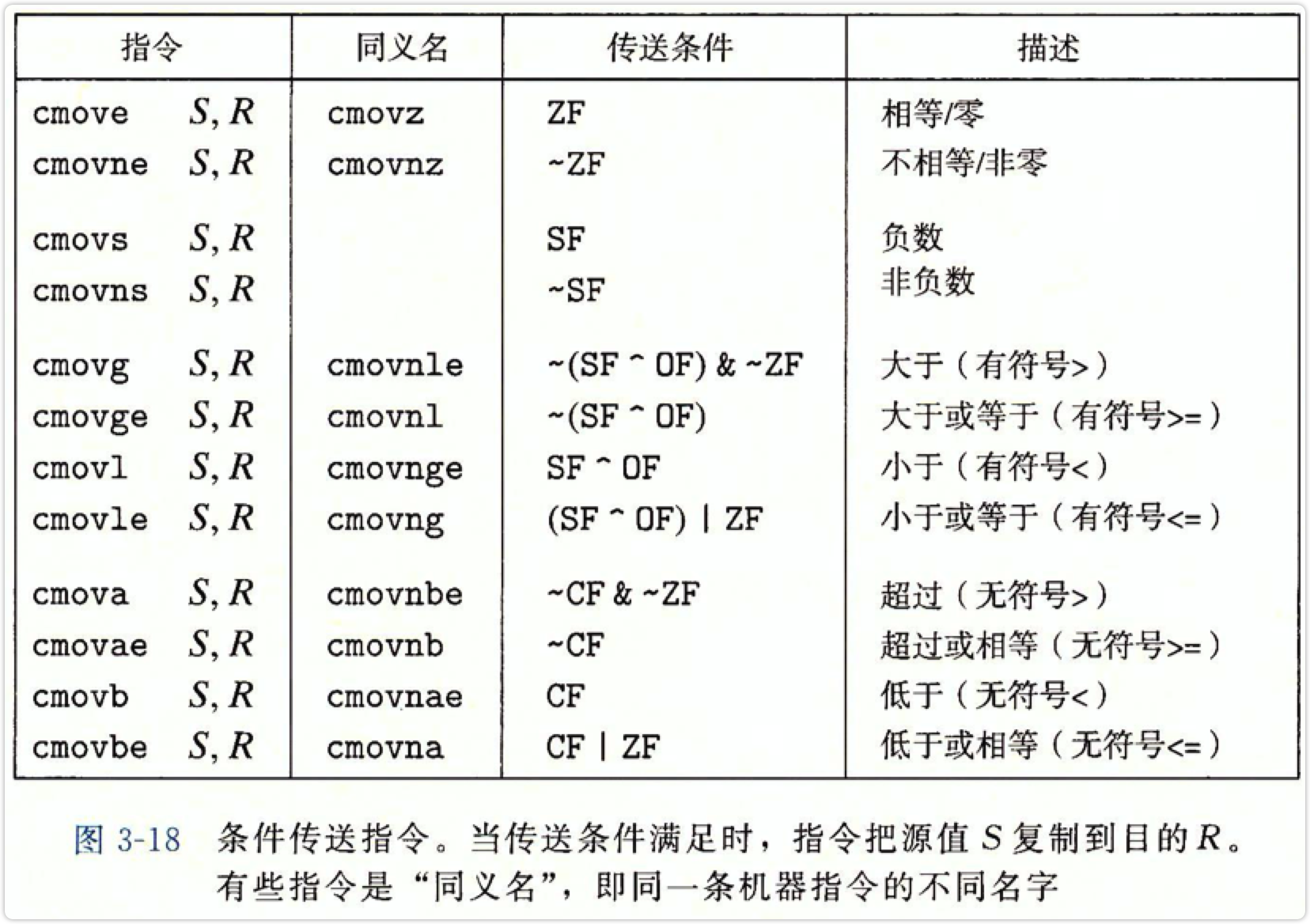
源是寄存器/内存,目的只能是寄存器,不支持单字节传送。
其实这里还有一大堆东西,但总结一下就是教你怎么看懂汇编。
白兰不想看,不写。
栈帧
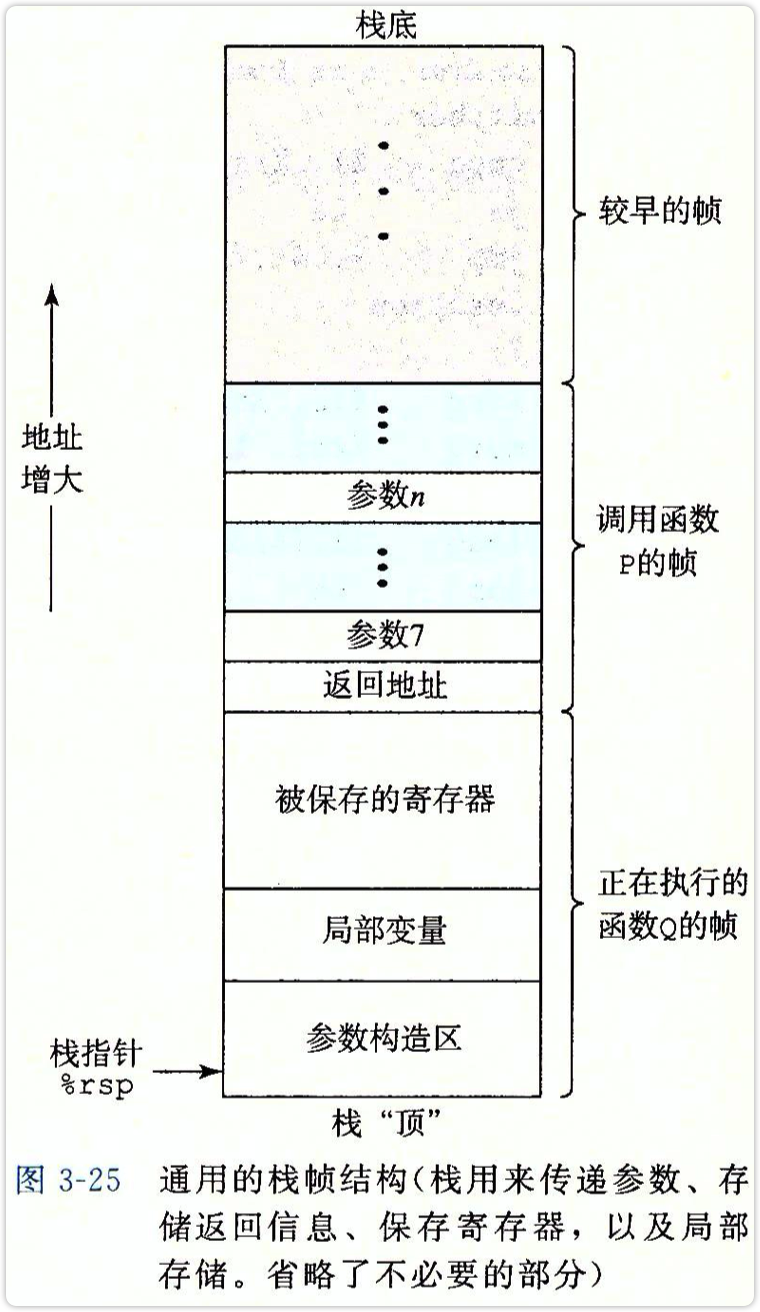
令Q作为被调用的函数,A为调用Q指令的下一条指令的地址。PC计数器中存储下一条将要执行的指令的地址。
call Q指令会把地址A压入栈中,并把PC设置为Q的起始地址。压入的地址A是紧跟在call指令后面的那条指令的地址。对应的指令ret会从栈中弹出地址A,并把PC设置为A。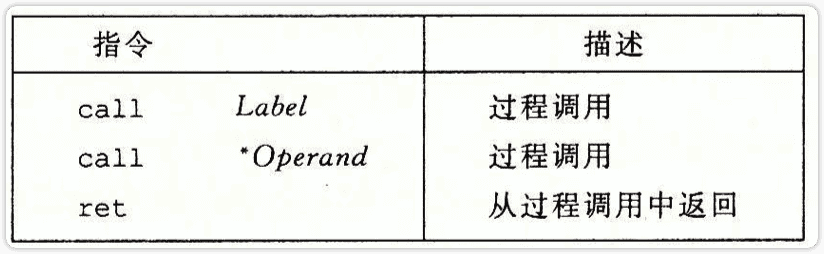
如图。call指令也可以是间接的。
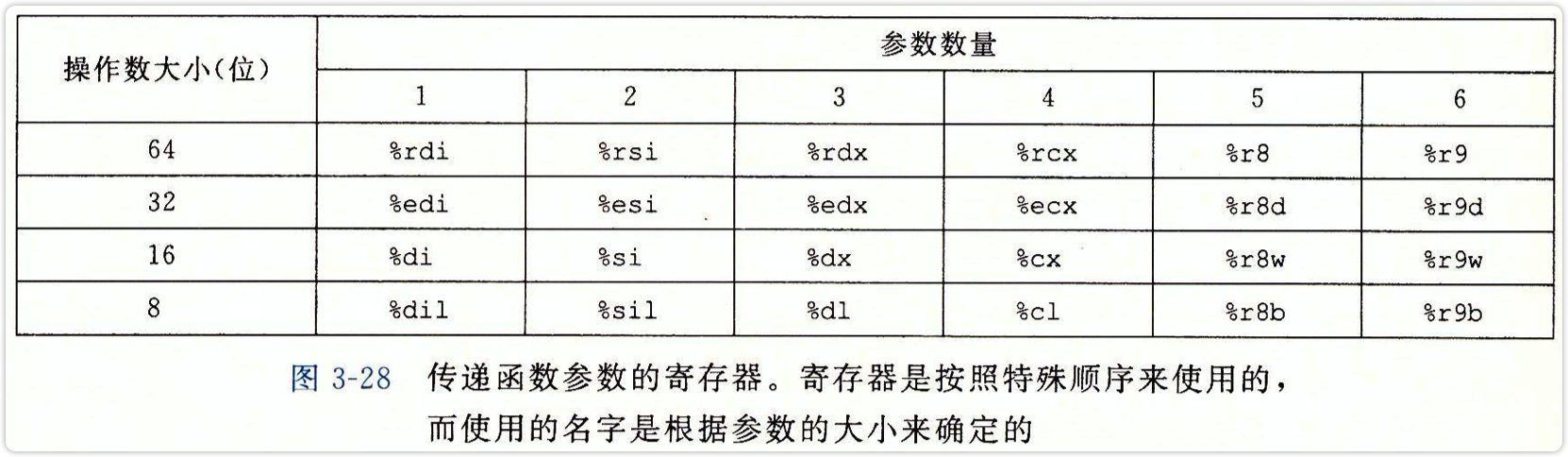
传参时寄存器的对应顺序如图。
如果参数超过6个,那么把前六个参数放入寄存器中,剩下的参数传到栈帧,而第七个参数位于栈顶。传参是在call指令之前完成的。
通过栈传递参数时,所有的数据大小都向8的倍数看齐。
根据惯例,寄存器%rbx、%rbp和%r12~%r15被划分为被调用者保存寄存器。当过程P调用过程Q时,Q必须保存这些寄存器的值,保证它们的值在Q返回到P时与Q被调用时是一样的。过程Q保存一个寄存器的值不变,要么就是根本不去改变它,要么就是把原始值压入栈中,改变寄存器的值,然后在返回前从栈中弹出旧值。压入寄存器的值会在栈帧中创建标号为“保存的寄存器”的一部分。
所有其他的寄存器,除了栈指针%rsp,都分类为调用者保存寄存器。这就意味着任何函数都能修改它们。
栈中的寄存器(栈帧的简略版)
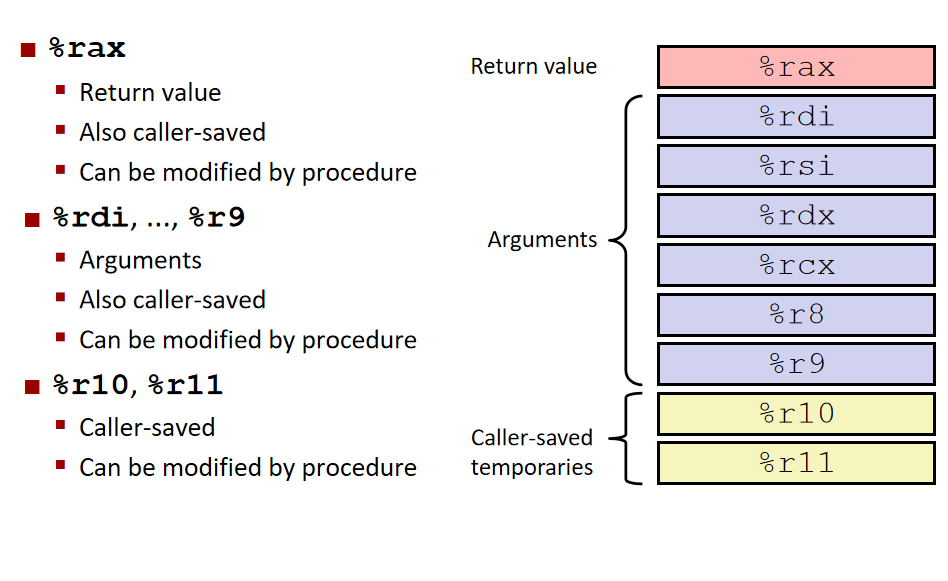
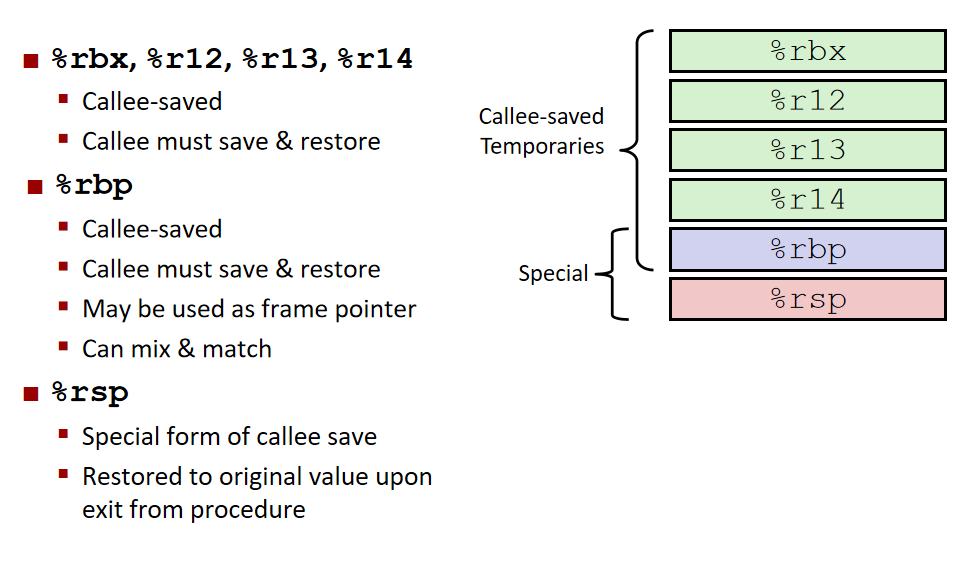
- 倒也不用全记,但顺序要记,传进来的参数按顺序都进了哪些寄存器。
rdi,rsi,rdx,rcx,r8,r9 - 传参只进这六个,多的就用栈帧存。
然后还有几个特殊的:
rax:存储返回值
rsp:指向栈顶
rbp:有时候用来指栈底 - 然后被谁保存的问题:
- 调用者(caller)保存的寄存器:
rax,rdi,rsi,rdx,rcx,r8,r9,r10,r11 - 被调用者(callee)保存的寄存器:
rbx,r12,r13,r14,rbp,rsp
- 调用者(caller)保存的寄存器: