类似于if-else的分支分类处理方法。
机器学习估计暂时只会看这个了,属于是定点学习。
source:
【机器学习15】决策树模型详解
决策树算法–C4.5算法
CART算法
【十大经典数据挖掘算法】CART
西瓜书。
下面这个有代码可以参考,但是是jvav的:
统计学习方法(五)——决策树
熵
目标:通过一种衡量标准,来计算通过不同特征进行分支选择后的分类情况,找出来最好的那个当成根节点,以此类推。
衡量标准-熵:熵是表示随机变量不确定性的度量
计算一种分类方式对应的熵:
其中指的是对于分类结果中下标为的类型出现的概率。
eg.

这里以上面的例子进行公式解读,都只单看左侧的分类结果,对于B中的,只有三角,也就是一个分类结果,即为取值概率,这里就为100%,再结合一下log函数,其值在[0,1]之间是递增的,那么前面加上一个负号就是递减,因此这个B右侧分类结果带入计算公式值就是0,而0又是这个公式值中的最小值。再看A中左侧的分类结果,由于存在着两种情况,因此公式中就出现了累加,分别计算两种结果的熵值情况,最后汇总,其值必然是大于0的,故A中的类别较多,熵值也就大了不少,B中的类别较为稳定。
判断此次决策判断的好坏的依据:决策后各个分类结果的熵值和比较初始情况的熵值的减小程度
eg.
还拿A举例,最初的状态五个三角三个圆(对应一个熵值1),经过决策之后形成左侧三个三角两个圆(对应熵值2)和右侧的两个三角一个圆(对应熵值3),如果最后的熵值2+熵值3 < 熵值1,那么就可以判定这次分类较好,比原来有进步,也就是通过对比熵值(不确定性)减少的程度判断此次决策判断的好坏,不是只看分类后熵值的大小,而是要看决策前后熵值变化的情况。
信息增益:表示特征X使得类Y的不确定性减少的程度。
决策树构造实例
这里给官网的案例看看:

找根节点时有四种划分方式:

看看历史数据的熵值:
一般log函数的底取2,要求计算的时候统一底数即可
然后拿第一个特征举例:
outlook = sunny: 0.971;
outlook = overcast: 0;
outlook = rainy: 0.971;
考虑到outlook取到这三个特征的概率不同,考虑占比,最终的熵值计算为:
信息增益:从0.940下降到了0.693,则对应的信息增益为
同理,依次得到:
因此根节点选择outlook,之后选择子节点也是同样的流程。依次操作,最终可以得到整个决策树。
信息增益率和gini系数
如果使用ID作为节点来分类数据,这样每个叶子都只有一个数据,这样得到的熵值是最小的,但是这种分类方法不具备现实意义,无法区分得到任何信息。
而这种仅靠信息增益无法解决的问题,就采用了信息增益率和gini系数。
这里介绍一下构建决策树中使用的算法(至于前面的英文称呼,知道是一种指代关系就可以了,比如说的信息增益也可以使用ID3进行表示):
| 英文 |
中文 |
| ID3 |
信息增益 (对取值较多的属性有所偏好) |
| C4.5 |
信息增益率 (解决了ID3问题,考虑了自身熵) |
| CART |
使用gini系数作为衡量标准,计算公式: |
这里提到的自身熵问题就是指类似于上面的ID分类的问题(即可取值较多的属性引发的问题)
直接给ID的生成算法流程:

ID3算法只有树的生成,所以该算法生成的树容易产生过拟合。
剪枝方法
决策树可以无限细分来满足所有的分类结果,但是无限细分会导致分类过多,从而在最后预测的时候表现反而不好,因此要进行剪枝,控制模型的复杂程度。
剪枝策略:预剪枝(边建立决策树边进行剪枝的操作,比较实用)、后剪枝(当建立完成后再进行剪枝操作)
预剪枝方式:限制深度(比如指定到某一具体数值后不再进行分裂)、叶子节点个数、叶子节点样本数、信息增益量等
后剪枝方式(CART):通过一定的衡量标准,,叶子节点越多,损失越大
eg.

按照计算公式:
分裂之后就是两个叶子节点相加
最后就变成了比较这两次取得的数值,值越大代表着损失越大,也就越不好,取值的大小是取决于我们给定的α值,α值给出的越大,模型越会控制过拟合。
分类、回归任务
区别在于叶子节点中的类型是由什么所决定的。
分类任务是有叶子节点中数据的众数决定的,少数服从多数,加入某叶子节点中有10个“-”,2个“+”,则认定该叶子节点分类为“-”
回归任务和分类任务的做法几乎是一样的,但是评估的方式是不一样的,回归是采用方差进行衡量的,而不是信息熵或者基尼系数。方差越小则方案更优。
那么既然是回归问题也就避免不了数据取值,叶子节点中的数值计算的方式就为各个数据的平均数。
C4.5算法
引入了信息增益率,对应的公式为:
其中,k个值。假设用A来对样本集D进行划分,得到了K个分支节点,其中第k个节点中包含了D中所有取值为的样本,记为.
通常,属性A的可能取值数越多(即K越大),则IV(A)的值通常会越大。
信息增益率准则对可取值数目较少的属性有所偏好。所以,C4.5算法不是直接选择信息增益率最大的候选划分属性,而是先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择信息增益率最高的。
《统计学习方法》里给的比较系统的生成思路:

对连续特征的处理
当属性类型为离散型,无须对数据进行离散化处理;
当属性类型为连续型,则需要对数据进行离散化处理。具体思路如下:
- m个样本的连续特征A有m个值,从小到大排列为,取相邻两样本值的平均数做划分点,一共有m-1个,其中第i个划分点Ti表示为:
- 分别计算以这m-1个点作为二元切分点时的信息增益率。选择信息增益率最大的点为该连续特征的最佳切分点。比如取到的信息增益率最大的点为,则小于的值为类别1,大于的值为类别2,这样就做到了连续特征的离散化。
剪枝
前剪枝不讲了,大概就那几个判断条件。
主要讲后剪枝。
C4.5算法采用悲观剪枝方法。根据剪枝前后的误判率来判定是否进行子树的修剪, 如果剪枝后与剪枝前相比其误判率是保持或者下降,则这棵子树就可以被替换为一个叶子节点。 因此,不需要单独的剪枝数据集。C4.5 通过训练数据集上的错误分类数量来估算未知样本上的错误率。
把一颗子树(具有多个叶子节点)的剪枝后用一个叶子节点来替代的话,在训练集上的误判率肯定是上升的,但是在新数据上不一定。于是我们需要把子树的误判计算加上一个经验性的惩罚因子。对于一颗叶子节点,它覆盖了N个样本,其中有E个错误,那么该叶子节点的错误率为(E+0.5)/N。这个0.5就是惩罚因子,那么一颗子树,它有L个叶子节点,那么该子树的误判率估计为:
其中,表示子树的每一个叶子节点的误判样本数量,L为叶子节点个数,为每一个叶子节点的样本数量。
这样的话,我们可以看到一颗子树虽然具有多个子节点,但由于加上了惩罚因子,所以子树的误判率计算未必占到便宜。剪枝后内部节点变成了叶子节点,其误判个数J也需要加上一个惩罚因子,变成J+0.5。
所以剪枝后的误判率为:
那么子树是否可以被剪枝就取决于剪枝后的错误是否在的标准误差内。对于样本的误判率e,可以估计成各种各样的分布模型,比如二项式分布或者是正态分布。
我们假设一棵树错误分类一个样本值为1,正确分类一个样本值为0,那么按照上面所述公式,树的误判次数就是伯努利分布,得到均值和标准差为:
相应的,假设剪枝后的误判次数也满足伯努利分布,那么
这里采用一种保守的分裂方案,即有足够大的置信度保证分裂后准确率比不分裂时的准确率高时才分裂,否则就不分裂–也就是应该剪枝。
如果要分裂(即不剪枝)至少要保证分裂后的误判数E(子树误判次数)要小于不分裂的误判数E(叶子节点的误判次数),而且为了保证足够高的置信度,加了一个标准差可以有95%的置信度,所以,要分裂(即不剪枝)需满足如下不等式
反之就是不分裂,也就是进行剪枝。
扒了个代码用来参考思路,但是没有剪枝
C4.5算法的优缺点
优点:产生的分类规则易于理解,准确率较高
缺点:
- C4.5只能用于分类
- C4.5是多叉树,用二叉树效率会提高;
- 在构造树的过程中,需要对数据集进行多次的顺序扫描和排序(尤其是对连续特征),因而导致算法的低效;
- 在选择分裂属性时没有考虑到条件属性间的相关性,只计算数据集中每一个条件属性与决策属性之间的期望信息,有可能影响到属性选择的正确性;
- C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
| from math import log
import operator
import numpy as np
def createDataSet():
"""构建数据集"""
dataSet = [['是', '单身', 125, '否'],
['否', '已婚', 100, '否'],
['否', '单身', 70, '否'],
['是', '已婚', 120, '否'],
['否', '离异', 95, '是'],
['否', '已婚', 60, '否'],
['是', '离异', 220, '否'],
['否', '单身', 85, '是'],
['否', '已婚', 75, '否'],
['否', '单身', 90, '是']]
labels = ['是否有房', '婚姻状况', '年收入(k)']
return dataSet, labels
def calcShannonEnt(dataSet):
"""
计算给定数据集的香农熵
:param dataSet:给定的数据集
:return:返回香农熵
"""
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for label in labelCounts.keys():
prob = float(labelCounts[label])/numEntries
shannonEnt -= prob*log(prob, 2)
return shannonEnt
def majorityCnt(classList):
"""获取出现次数最好的分类名称"""
classCount = {}
classList = np.mat(classList).flatten().A.tolist()[0]
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def splitDataSet(dataSet, axis, value):
"""对离散型特征划分数据集"""
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def splitContinuousDataSet(dataSet, axis, value, direction):
"""对连续型特征划分数据集"""
subDataSet = []
for featVec in dataSet:
if direction == 0:
if featVec[axis] > value:
reduceData = featVec[:axis]
reduceData.extend(featVec[axis + 1:])
subDataSet.append(reduceData)
if direction == 1:
if featVec[axis] <= value:
reduceData = featVec[:axis]
reduceData.extend(featVec[axis + 1:])
subDataSet.append(reduceData)
return subDataSet
def chooseBestFeatureToSplit(dataSet, labels):
"""选择最好的数据集划分方式"""
baseEntropy = calcShannonEnt(dataSet)
baseGainRatio = 0.0
bestFeature = -1
numFeatures = len(dataSet[0]) - 1
bestSplitDic = {}
for i in range(numFeatures):
featVals = [example[i] for example in dataSet]
if type(featVals[0]).__name__ == 'float' or type(
featVals[0]).__name__ == 'int':
sortedFeatVals = sorted(featVals)
splitList = []
for j in range(len(featVals) - 1):
splitList.append(
(sortedFeatVals[j] + sortedFeatVals[j + 1]) / 2.0)
for j in range(len(splitList)):
newEntropy = 0.0
value = splitList[j]
greaterSubDataSet = splitContinuousDataSet(dataSet, i, value, 0)
smallSubDataSet = splitContinuousDataSet(dataSet, i, value, 1)
prob0 = len(greaterSubDataSet) / float(len(dataSet))
newEntropy += prob0 * calcShannonEnt(greaterSubDataSet)
prob1 = len(smallSubDataSet) / float(len(dataSet))
newEntropy += prob1 * calcShannonEnt(smallSubDataSet)
splitInfo = 0.0
splitInfo -= prob0 * log(prob0, 2)
splitInfo -= prob1 * log(prob1, 2)
gainRatio = float(baseEntropy - newEntropy) / splitInfo
if gainRatio > baseGainRatio:
baseGainRatio = gainRatio
bestSplit = j
bestFeature = i
bestSplitDic[labels[i]] = splitList[bestSplit]
else:
uniqueVals = set(featVals)
splitInfo = 0.0
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
splitInfo -= prob * log(prob, 2)
newEntropy += prob * calcShannonEnt(subDataSet)
if splitInfo == 0.0:
continue
gainRatio = float(baseEntropy - newEntropy) / splitInfo
if gainRatio > baseGainRatio:
bestFeature = i
baseGainRatio = gainRatio
if type(dataSet[0][bestFeature]).__name__ == 'float' or type(
dataSet[0][bestFeature]).__name__ == 'int':
bestFeatValue = bestSplitDic[labels[bestFeature]]
if type(dataSet[0][bestFeature]).__name__ == 'str':
bestFeatValue = labels[bestFeature]
return bestFeature, bestFeatValue
def createTree(dataSet, labels):
"""创建C4.5树"""
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeature, bestFeatValue = chooseBestFeatureToSplit(dataSet, labels)
if bestFeature == -1:
return majorityCnt(classList)
bestFeatLabel = labels[bestFeature]
myTree = {bestFeatLabel: {}}
subLabels = labels[:bestFeature]
subLabels.extend(labels[bestFeature + 1:])
if type(dataSet[0][bestFeature]).__name__ == 'str':
featVals = [example[bestFeature] for example in dataSet]
uniqueVals = set(featVals)
for value in uniqueVals:
reduceDataSet = splitDataSet(dataSet, bestFeature, value)
myTree[bestFeatLabel][value] = createTree(reduceDataSet, subLabels)
if type(dataSet[0][bestFeature]).__name__ == 'int' or type(
dataSet[0][bestFeature]).__name__ == 'float':
value = bestFeatValue
greaterSubDataSet = splitContinuousDataSet(dataSet, bestFeature, value, 0)
smallSubDataSet = splitContinuousDataSet(dataSet, bestFeature, value, 1)
myTree[bestFeatLabel]['>' + str(value)] = createTree(greaterSubDataSet, subLabels)
myTree[bestFeatLabel]['<=' + str(value)] = createTree(smallSubDataSet, subLabels)
return myTree
if __name__ == '__main__':
dataSet, labels = createDataSet()
mytree = createTree(dataSet, labels)
print("最终构建的C4.5分类树为:\n", mytree)
|
CART
不同于C4.5,CART本质是对特征空间进行二元划分(即CART生成的决策树是一棵二叉树),并能够对标量属性(nominal attribute)与连续属性(continuous attribute)进行分裂。
CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子结点都有两个分支,因此CART算法生成的决策树是结构简洁的二叉树。由于CART算法构成的是一个二叉树,它在每一步的决策时只能是“是”或者“否”,即使一个feature有多个取值,也是把数据分为两部分。在CART算法中主要分为两个步骤
CART生成
CART对特征属性进行二元分裂。特别地,当特征属性为标量或连续时,可选择如下方式分裂:
An instance goes left if CONDITION, and goes right otherwise
即满足条件左分,不满足条件右分。

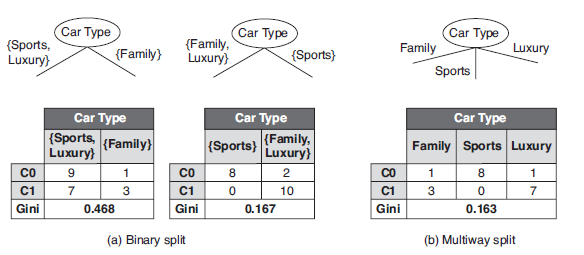
标量属性
进行分裂的CONDITION可置为不等于属性的某值;比如,标量属性Car Type取值空间为{Sports, Family, Luxury},二元分裂与多路分裂如下:
连续属性
CONDITION可置为不大于ε;比如,连续属性Annual Income,ε取属性相邻值的平均值,其二元分裂结果如下:
接下来,需要解决的问题:应该选择哪种特征属性及定义CONDITION,才能分类效果比较好。CART采用Gini指数来度量分裂时的不纯度,之所以采用Gini指数,是因为较于熵而言其计算速度更快一些。对决策树的节点t,Gini指数计算公式如下:
Gini指数即为与类别的概率平方之和的差值,反映了样本集合的不确定性程度。Gini指数越大,样本集合的不确定性程度越高。分类学习过程的本质是样本不确定性程度的减少(即熵减过程),故应选择最小Gini指数的特征分裂。父节点对应的样本集合为,CART选择特征分裂为两个子节点,对应集合为和分裂后的Gini指数定义如下:
剪枝
上面讲剪枝的时候提到过CART的剪枝公式,也就是
CART算法采用递归的方法进行剪枝,具体办法:

看不太懂,换个说法。
计算子树的损失函数与之前相比稍加调整:
其中,T为任意的子树,C(T)为对训练数据的预测误差(如基尼指数、平方误差),|T| 为子树 T 的叶结点的个数,是子树整体的损失函数。
其中α为非负数,它权衡着模型对训练数据的拟合程度与模型本身复杂度两者之间的关系。
α|T| 项相当于对子树的叶结点的个数进行惩罚:
Ⅰ. α 越大,对子树叶结点的数量惩罚力度越大,迫使子树有更少的叶结点,即越迫使子树进行剪枝;
Ⅱ. α 越小,则越放松了对子树叶结点数量的压迫,越允许子树有更多的叶结点,即越倾向于不剪枝。
当 α 从 0 慢慢增大到 ∞ 时,最优子树会慢慢从最开始的整体树,一点一点剪枝,直到变成单结点树。 具体数学表述如下:

则可以说

所以随着 α 的增大,决策树会不断地进行剪枝,共剪枝 n 次,形成 n+1个子树序列。
